


How to use PostgreSQL in your serverless app
In this example we will look at how to use PostgreSQL in our serverless app using SST. We’ll be creating a simple hit counter using Amazon Aurora Serverless.
Requirements
- Node.js 16 or later
- We’ll be using TypeScript
- An AWS account with the AWS CLI configured locally
Create an SST app
 Let’s start by creating an SST app.
Let’s start by creating an SST app.
$ npx create-sst@latest --template=base/example rest-api-postgresql
$ cd rest-api-postgresql
$ npm install
By default, our app will be deployed to the us-east-1 AWS region. This can be changed in the sst.config.ts in your project root.
import { SSTConfig } from "sst";
export default {
config(_input) {
return {
name: "rest-api-postgresql",
region: "us-east-1",
};
},
} satisfies SSTConfig;
Project layout
An SST app is made up of two parts.
-
stacks/— App InfrastructureThe code that describes the infrastructure of your serverless app is placed in the
stacks/directory of your project. SST uses AWS CDK, to create the infrastructure. -
packages/functions/— App CodeThe code that’s run when your API is invoked is placed in the
packages/functions/directory of your project.
Adding PostgreSQL
Amazon Aurora Serverless is an auto-scaling managed relational database that supports PostgreSQL.
Replace the stacks/ExampleStack.ts with the following.
import { Api, RDS, StackContext } from "sst/constructs";
export function ExampleStack({ stack }: StackContext) {
const DATABASE = "CounterDB";
// Create the Aurora DB cluster
const cluster = new RDS(stack, "Cluster", {
engine: "postgresql10.14",
defaultDatabaseName: DATABASE,
migrations: "services/migrations",
});
}
This creates an RDS Serverless cluster. We also set the database engine to PostgreSQL. The database in the cluster that we’ll be using is called CounterDB (as set in the defaultDatabaseName variable).
The migrations prop should point to the folder where your migration files are. The RDS construct uses Kysely to run and manage schema migrations. You can read more about migrations here.
Setting up the Database
Let’s create a migration file that creates a table called tblcounter.
Create a migrations folder inside the services/ folder.
Let’s write our first migration file, create a new file called first.mjs inside the newly created services/migrations folder and paste the below code.
import { Kysely } from "kysely";
/**
* @param db {Kysely<any>}
*/
export async function up(db) {
await db.schema
.createTable("tblcounter")
.addColumn("counter", "text", (col) => col.primaryKey())
.addColumn("tally", "integer")
.execute();
await db
.insertInto("tblcounter")
.values({
counter: "hits",
tally: 0,
})
.execute();
}
/**
* @param db {Kysely<any>}
*/
export async function down(db) {
await db.schema.dropTable("tblcounter").execute();
}
Setting up the API
Now let’s add the API.
Add this below the cluster definition in stacks/ExampleStack.ts.
// Create a HTTP API
const api = new Api(stack, "Api", {
defaults: {
function: {
bind: [cluster],
},
},
routes: {
"POST /": "packages/functions/src/lambda.handler",
},
});
// Show the resource info in the output
stack.addOutputs({
ApiEndpoint: api.url,
SecretArn: cluster.secretArn,
ClusterIdentifier: cluster.clusterIdentifier,
});
Our API simply has one endpoint (the root). When we make a POST request to this endpoint the Lambda function called handler in packages/functions/src/lambda.ts will get invoked.
We’ll also bind our database cluster to our API.
Reading from our database
Now in our function, we’ll start by reading from our PostgreSQL database.
Replace packages/functions/src/lambda.ts with the following.
import { Kysely } from "kysely";
import { DataApiDialect } from "kysely-data-api";
import { RDSData } from "@aws-sdk/client-rds-data";
import { RDS } from "sst/node/rds";
interface Database {
tblcounter: {
counter: string;
tally: number;
};
}
const db = new Kysely<Database>({
dialect: new DataApiDialect({
mode: "postgres",
driver: {
database: RDS.Cluster.defaultDatabaseName,
secretArn: RDS.Cluster.secretArn,
resourceArn: RDS.Cluster.clusterArn,
client: new RDSData({}),
},
}),
});
export async function handler() {
const record = await db
.selectFrom("tblcounter")
.select("tally")
.where("counter", "=", "hits")
.executeTakeFirstOrThrow();
let count = record.tally;
return {
statusCode: 200,
body: count,
};
}
We are using the Data API. It allows us to connect to our database over HTTP using the kysely-data-api.
For now we’ll get the number of hits from a table called tblcounter and return it.
Let’s install the new packages in the packages/functions/ folder.
$ npm install kysely kysely-data-api @aws-sdk/client-rds-data
And test what we have so far.
Starting your dev environment
SST features a Live Lambda Development environment that allows you to work on your serverless apps live.
$ npm run dev
The first time you run this command it’ll take a couple of minutes to deploy your app and a debug stack to power the Live Lambda Development environment.
===============
Deploying app
===============
Preparing your SST app
Transpiling source
Linting source
Deploying stacks
dev-rest-api-postgresql-ExampleStack: deploying...
✅ dev-rest-api-postgresql-ExampleStack
Stack dev-rest-api-postgresql-ExampleStack
Status: deployed
Outputs:
SecretArn: arn:aws:secretsmanager:us-east-1:087220554750:secret:CounterDBClusterSecret247C4-MhR0f3WMmWBB-dnCizN
ApiEndpoint: https://u3nnmgdigh.execute-api.us-east-1.amazonaws.com
ClusterIdentifier: dev-rest-api-postgresql-counterdbcluster09367634-1wjmlf5ijd4be
The ApiEndpoint is the API we just created. While the SecretArn is what we need to login to our database securely. The ClusterIdentifier is the id of our database cluster.
Before we can test our endpoint let’s create the tblcounter table in our database.
Running migrations
You can run migrations from the SST Console. The SST Console is a web based dashboard to manage your SST apps. Learn more about it in our docs.
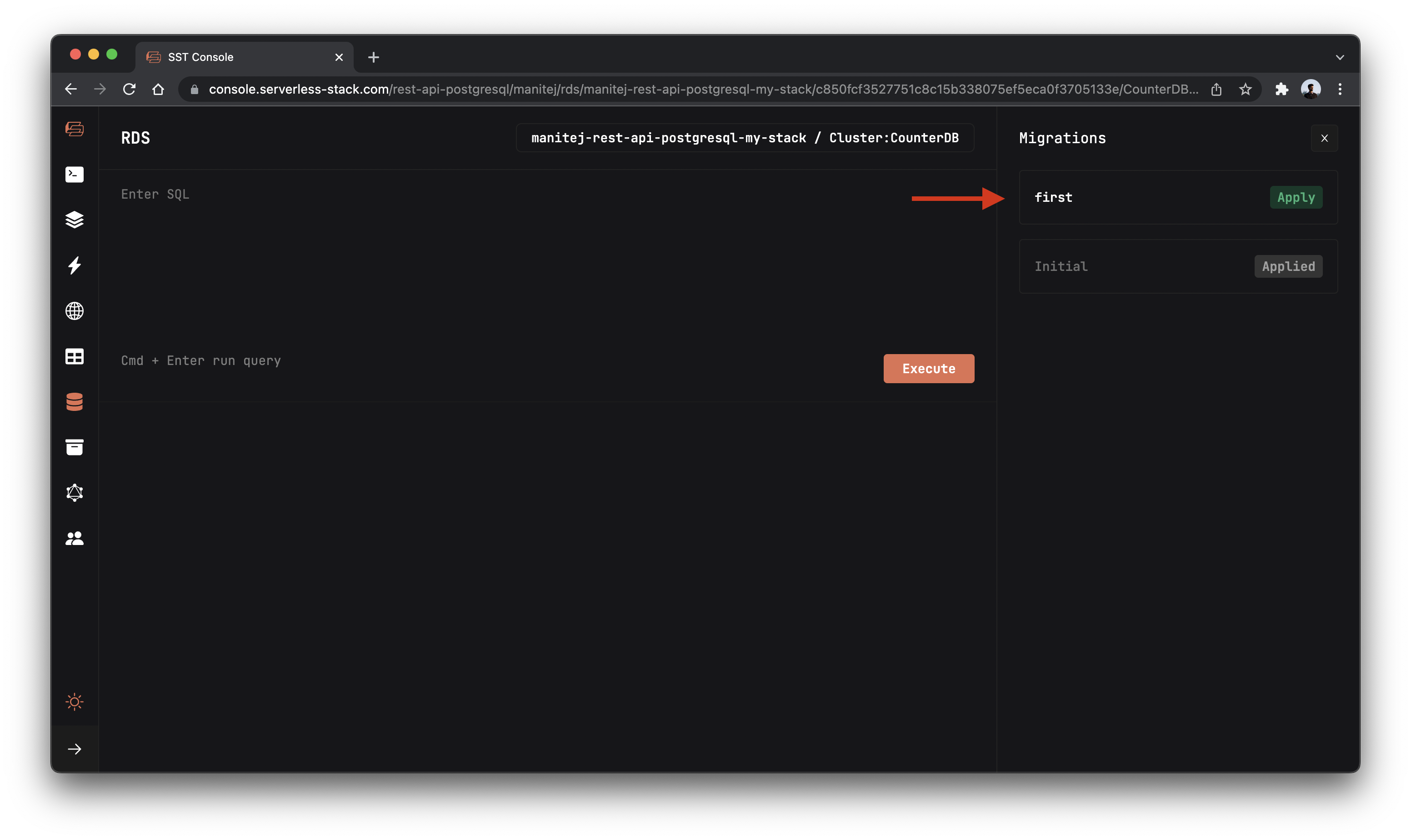
Go to the RDS tab and click the Migrations button on the top right corner.
It will list out all the migration files in the specified folder.
Now to apply the migration that we created, click on the Apply button beside to the migration name.
To confirm if the migration is successful, let’s display the tblcounter table by running the below query.
SELECT * FROM tblcounter
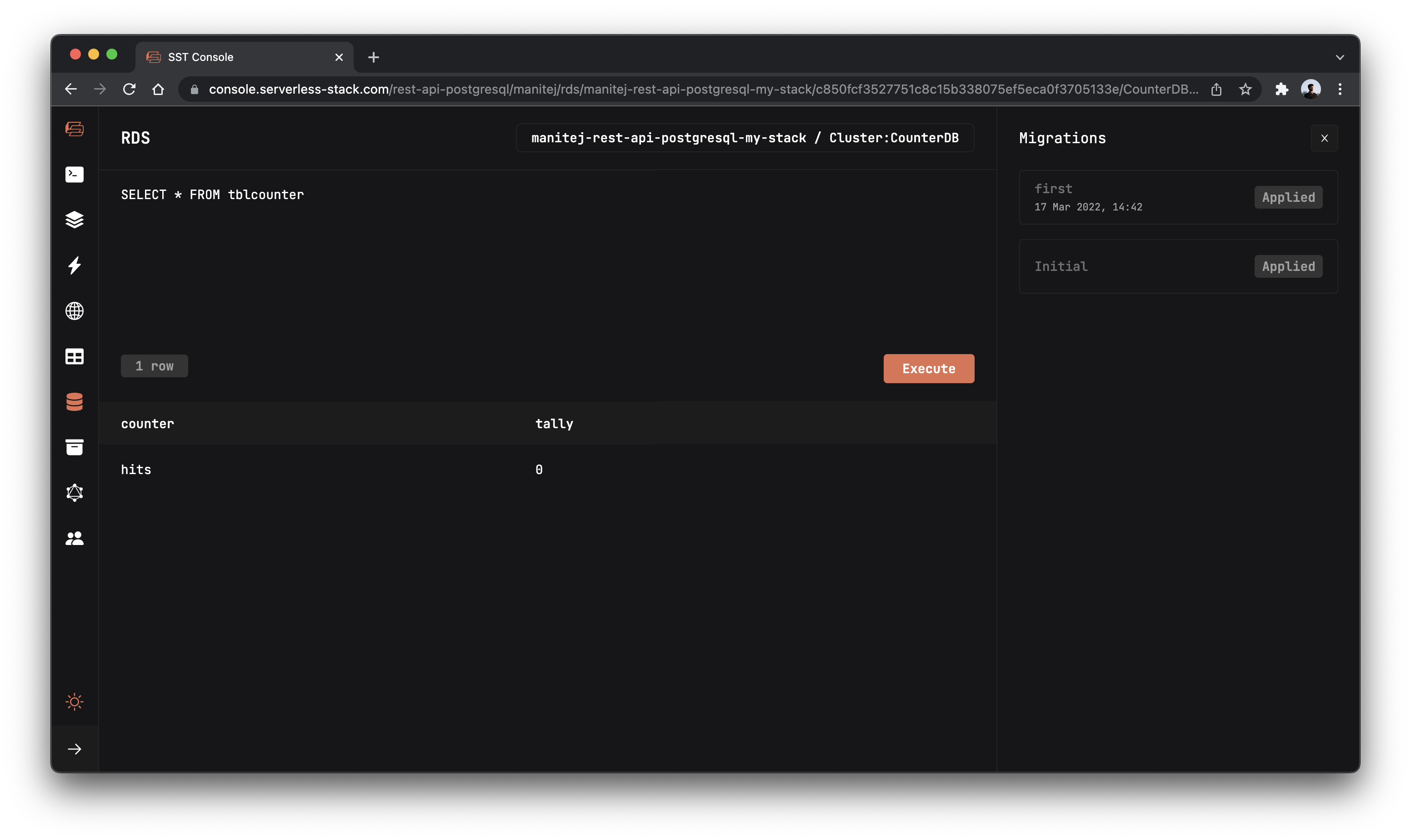
You should see the table with 1 row .
Test our API
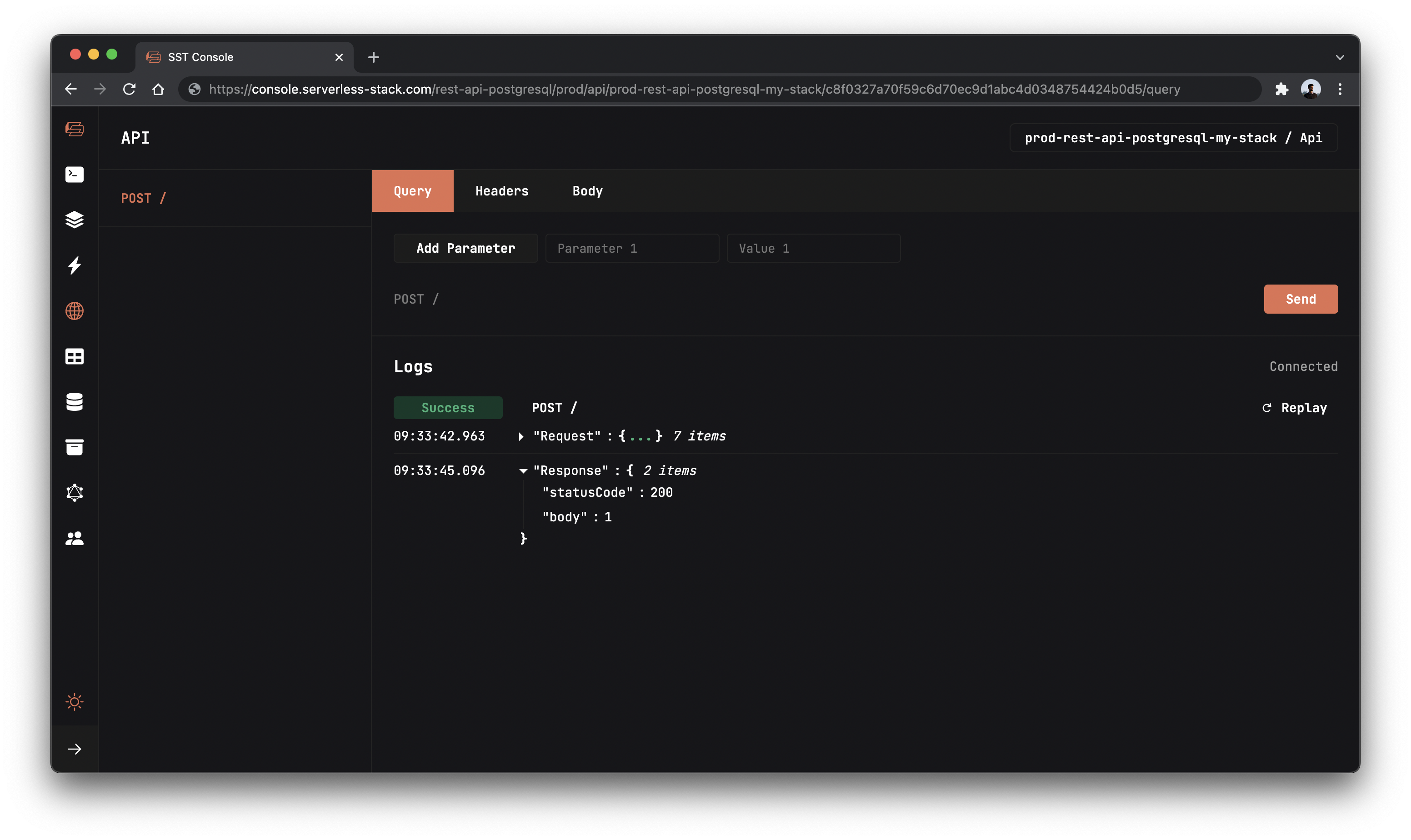
Now that our table is created, let’s test our endpoint with the SST Console.
Go to the API tab and click Send button to send a POST request.
Note, The API explorer lets you make HTTP requests to any of the routes in your Api construct. Set the headers, query params, request body, and view the function logs with the response.
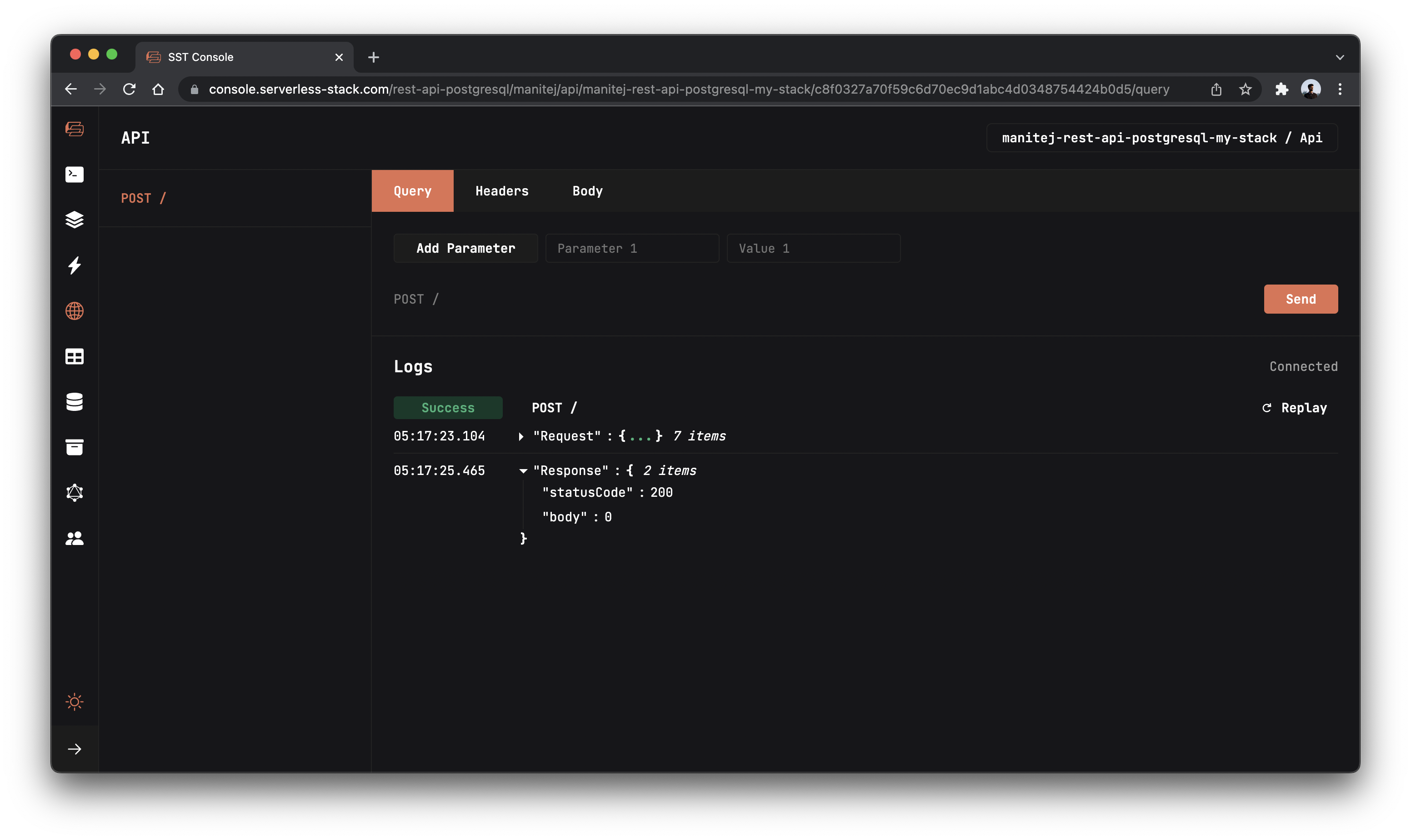
You should see a 0 in the response body.
Writing to our table
So let’s update our table with the hits.
Add this above the return statement in packages/functions/src/lambda.ts.
await db
.updateTable("tblcounter")
.set({
tally: ++count,
})
.execute();
Here we are updating the hits row’s tally column with the increased count.
And now if you head over to your console and make a request to our API. You’ll notice the count increase!
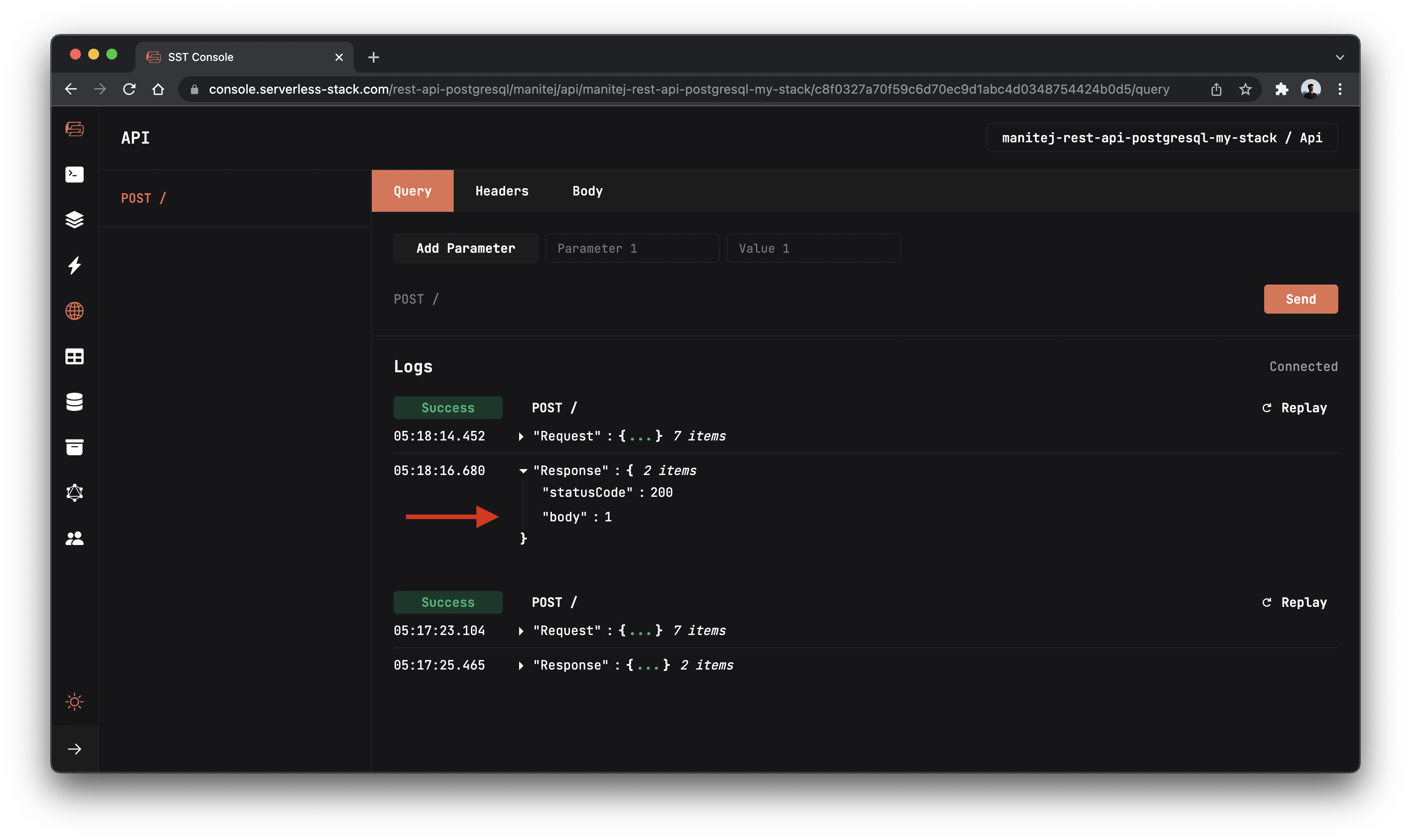
Deploying to prod
To wrap things up we’ll deploy our app to prod.
$ npx sst deploy --stage prod
This allows us to separate our environments, so when we are working in dev, it doesn’t break the API for our users.
Run the below command to open the SST Console in prod stage to test the production endpoint.
npx sst console --stage prod
Go to the API tab and click Send button to send a POST request.
Cleaning up
Finally, you can remove the resources created in this example using the following commands.
$ npx sst remove
$ npx sst remove --stage prod
Conclusion
And that’s it! We’ve got a completely serverless hit counter. And we can test our changes locally before deploying to AWS! Check out the repo below for the code we used in this example. And leave a comment if you have any questions!
Example repo for reference
github.com/sst/sst/tree/master/examples/rest-api-postgresqlFor help and discussion
Comments on this exampleMore Examples
APIs
-
REST API
Building a simple REST API.
-
WebSocket API
Building a simple WebSocket API.
-
Go REST API
Building a REST API with Golang.
-
Custom Domains
Using a custom domain in an API.
Web Apps
-
React.js
Full-stack React app with a serverless API.
-
Next.js
Full-stack Next.js app with DynamoDB.
-
Vue.js
Full-stack Vue.js app with a serverless API.
-
Svelte
Full-stack SvelteKit app with a serverless API.
-
Gatsby
Full-stack Gatsby app with a serverless API.
-
Angular
Full-stack Angular app with a serverless API.
Mobile Apps
GraphQL
Databases
-
DynamoDB
Using DynamoDB in a serverless API.
-
MongoDB Atlas
Using MongoDB Atlas in a serverless API.
-
CRUD DynamoDB
Building a CRUD API with DynamoDB.
-
PlanetScale
Using PlanetScale in a serverless API.
Authentication
Using SST Auth
-
Facebook Auth
Adding Facebook auth to a full-stack serverless app.
-
Google Auth
Adding Google auth to a full-stack serverless app.
Using Cognito Identity Pools
-
Cognito IAM
Authenticating with Cognito User Pool and Identity Pool.
-
Facebook Auth
Authenticating a serverless API with Facebook.
-
Twitter Auth
Authenticating a serverless API with Twitter.
-
Auth0 IAM
Authenticating a serverless API with Auth0.
Using Cognito User Pools
-
Cognito JWT
Adding JWT authentication with Cognito.
-
Auth0 JWT
Adding JWT authentication with Auth0.
-
Google Auth
Authenticating a full-stack serverless app with Google.
-
GitHub Auth
Authenticating a full-stack serverless app with GitHub.
-
Facebook Auth
Authenticating a full-stack serverless app with Facebook.
Async Tasks
-
Cron
A simple serverless Cron job.
-
Queues
A simple queue system with SQS.
-
Pub/Sub
A simple pub/sub system with SNS.
-
Resize Images
Automatically resize images uploaded to S3.
-
Kinesis data streams
A simple Kinesis Data Stream system.
-
EventBus
A simple EventBridge system with EventBus.
Editors
-
Debug With VS Code
Using VS Code to debug serverless apps.
-
Debug With WebStorm
Using WebStorm to debug serverless apps.
-
Debug With IntelliJ
Using IntelliJ IDEA to debug serverless apps.
Monitoring
Miscellaneous
-
Lambda Layers
Using the @sparticuz/chromium layer to take screenshots.
-
Middy Validator
Use Middy to validate API request and responses.